1 全文检索 和 索引
1.1 索引
将非结构化数据中的一部分信息 取出来,重新组织,使其变得有一定结构,然后对此有 一定结构的数据进行搜索,从而达到搜索相对较快的目的。这部分从非结构化数据中 取出的然 后重新组织的信息,我们称之索引。
例如:字典。字典的拼音表和部首检字表就相当于字典的索引,对每一个字的解释是非结 构化的,如果字典没有音节表和部首检字表,在茫茫辞海中找一个字只能顺序扫 。然而字的某 些信息可以 取出来进行结构化处理,比如读音,就比较结构化,分声母和韵母,分别只有几种 可以一一列举,于是将读音拿出来按一定的顺序排列,每一项读音都指向此字的详细解释的页数。 我们搜索时按结构化的拼音搜到读音,然后按其指向的页数,便可找到我们的非结构化数据—— 也即对字的解释。
1.2 全文检索
这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。
2 Lucene实现全文检索的流程
2.1 索引和搜索流程图
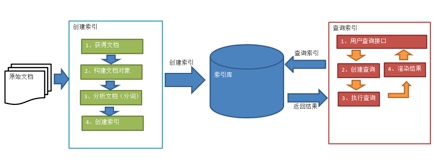
2.2 创建索引
将用户需要搜索的文档内容进行索引,索引存储在索引库中。索引库位于本地磁盘中。
2.2.1 获得原始文档
可以使用网络爬虫采集一定量的文本数据,比如新闻信息。采集后将数据从数据库中转移到本地磁盘中。
2.2.2 创建文档对象
获取原始内容的目的是为了索引,在索引前需要将原始内容创建成文档(Document),文档包括多个域Field和域中存储的内容。
我们可以将磁盘中的一个文件当成一个document,document中包含field和对应的value。
2.2.3 分析文档
分析的过程是经过对原始文档的提取单词、字母大小写转换、去除标点符号、去除停用词等过程成圣最终的与会单词。比如下面的文档的分析过程如下:
原文:Hello,welcome to the java world!
分析结果:Hello、welcome、java、world
每一个单词是一个term,不同的域中拆分出来的相同单词是不同的term。term中包含field和value。
分析过程中会涉及到分析器,用来根据语义进行分词,中文的较为复杂。
2.2.4 创建索引
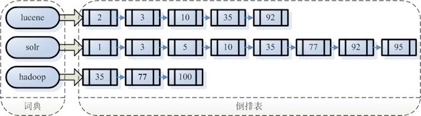
对所有文档分析得到的单词进行索引,索引的目的是为了搜索,最终要实现只搜索被索引的单词而找到Document。
传统的搜索方式是顺序扫描法,在Lucene中所使用的索引方法是倒排索引法。即根据索引值去查找文档,而不是去遍历文档来扫描关键字。
3 程序实现
3.1 准备工作
- 创建原始文档:在本地磁盘中创建一个目录,将原始文本存储于其中。
- 创建索引库:在本地磁盘中创建一个空目录,用于存储索引。
3.2 引入相关jar包(POM)
|
|
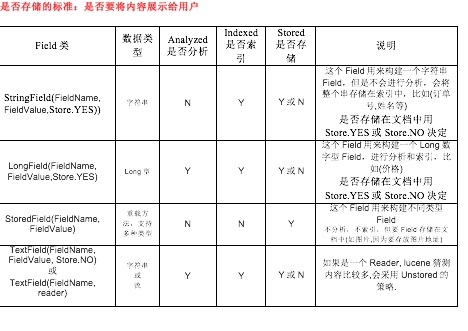
3.3 了解相关Field
3.4 测试代码
|
|
3.5 使用Luke工具查看索引库